Kafka와 메시지 큐는 분산 시스템에서 비동기 메시징을 처리하는 중요한 기술입니다. IT 면접에서는 메시지 큐의 개념, Kafka의 특징, 그리고 기존 메시지 큐(RabbitMQ, ActiveMQ 등)와의 차이점을 비교하는 질문이 자주 출제됩니다. 오늘은 Kafka와 메시지 큐의 개념과 차이를 살펴보겠습니다.

---
1. 메시지 큐(Message Queue)란?
메시지 큐는 비동기 메시지 전달을 위한 시스템으로, 생산자(Producer)와 소비자(Consumer) 간의 결합도를 낮추고 확장성을 높이는 역할을 합니다. 일반적으로 메시지를 버퍼링하고 관리하는 방식으로 동작하며, 대표적인 메시지 큐 시스템으로 RabbitMQ, ActiveMQ, Amazon SQS 등이 있습니다.
메시지 큐의 주요 특징:
비동기 통신 지원: 생산자가 메시지를 큐에 저장하면, 소비자가 나중에 이를 처리할 수 있음.
메시지 보장 기능: 메시지가 손실되지 않도록 저장하고, 특정 정책(예: At-Least-Once, Exactly-Once)으로 메시지를 전달함.
라우팅 및 필터링 기능: 특정 조건에 따라 메시지를 다양한 소비자에게 전달 가능.
---
2. Kafka란?
Apache Kafka는 고성능, 분산형 스트리밍 플랫폼으로, 메시지 큐의 기능을 포함하면서 대용량 데이터 스트리밍과 실시간 처리를 지원하는 메시징 시스템입니다.
Kafka의 주요 특징:
분산 아키텍처: 브로커(서버)들이 여러 개의 노드로 구성되어 고가용성을 보장함.
로그 기반 저장(Log-based Storage): 메시지가 일정 기간 동안 저장되며, 소비자가 필요할 때 읽을 수 있음.
빠른 처리 속도: 배치 처리 및 스트리밍 처리를 동시에 지원함.
대용량 데이터 처리: 수백만 TPS(초당 트랜잭션)를 처리할 수 있는 확장성을 가짐.
---
3. Kafka와 기존 메시지 큐의 차이점
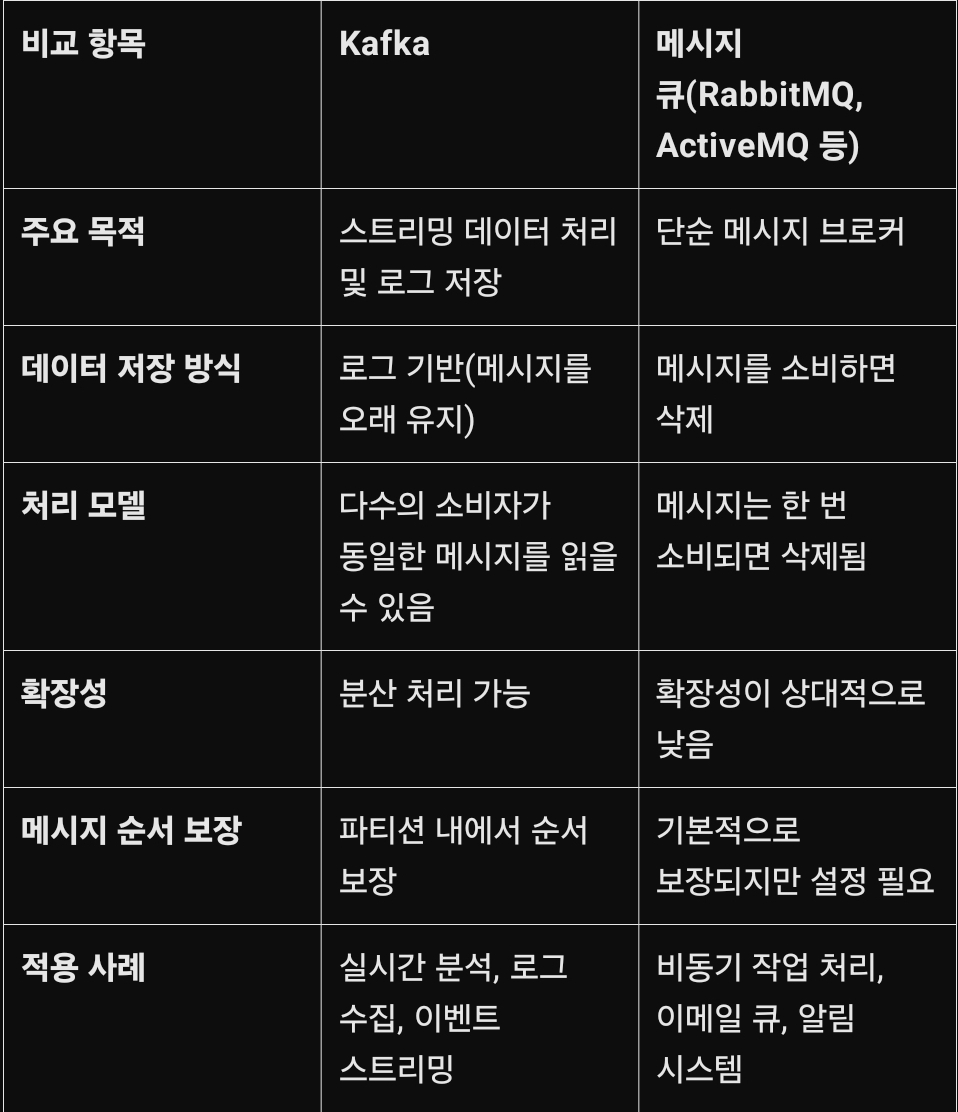
---
4. 면접에서 자주 묻는 질문
Q: 메시지 큐란 무엇이며, 왜 필요한가요?
A: 메시지 큐는 비동기 방식으로 데이터(메시지)를 전달하는 시스템으로, 생산자와 소비자가 직접 통신하지 않고 메시지 브로커를 통해 데이터를 주고받도록 합니다. 이를 통해 서비스 간 결합도를 낮추고 확장성을 높일 수 있습니다.
Q: Kafka와 RabbitMQ의 차이점은 무엇인가요?
A: Kafka는 로그 기반의 스트리밍 플랫폼으로, 대용량 데이터를 빠르게 처리하고 보존할 수 있는 기능이 있습니다. 반면, RabbitMQ는 전통적인 메시지 큐 시스템으로, 메시지를 소비하면 큐에서 삭제되는 방식이 일반적입니다. Kafka는 실시간 데이터 분석, 이벤트 스트리밍과 같은 대규모 데이터 처리에 적합하고, RabbitMQ는 비동기 작업 처리, 이메일 전송 등의 간단한 메시징 시스템에 적합합니다.
Q: Kafka는 어떤 방식으로 메시지를 저장하고 소비하나요?
A: Kafka는 토픽(Topic)이라는 논리적 저장소에 메시지를 저장하며, 각 토픽은 파티션(Partition)으로 분할되어 다수의 소비자가 동시에 메시지를 읽을 수 있습니다. Kafka는 기본적으로 메시지를 삭제하지 않고 유지하며, 소비자는 필요할 때 원하는 메시지를 가져가는 방식으로 동작합니다.
Q: Kafka에서 데이터 순서를 보장할 수 있나요?
A: Kafka는 파티션(Partition) 단위로 메시지의 순서를 보장합니다. 즉, 같은 파티션 내에서는 메시지가 순차적으로 처리되지만, 여러 개의 파티션에 메시지가 분산될 경우 순서가 보장되지 않을 수 있습니다. 이를 해결하기 위해 Key 기반 파티셔닝을 활용하면 특정 키(예: 사용자 ID)로 동일한 파티션에 메시지를 저장할 수 있습니다.
Q: Kafka의 장애 복구 및 고가용성을 보장하는 방법은 무엇인가요?
A: Kafka는 브로커(Broker) 간의 데이터 복제(replication) 기능을 제공하여 장애 발생 시 데이터를 보호할 수 있습니다. 리더(Leader) 브로커가 장애가 발생하면, 팔로워(Follower) 브로커가 자동으로 리더 역할을 수행하여 서비스가 중단되지 않도록 합니다. 또한, zookeeper를 이용한 클러스터 관리를 통해 안정적인 메시지 처리가 가능합니다.
---
5. 면접 준비 팁
Kafka와 RabbitMQ의 동작 방식과 차이점을 정리해 보세요.
직접 Kafka 클러스터를 구축하고 메시지를 주고받는 실습을 해보세요.
Kafka의 주요 개념(Producer, Consumer, Topic, Partition, Offset 등)을 이해하고 설명할 수 있도록 준비하세요.
다음 면접 준비 포스트에서는 "Redis의 주요 개념과 사용 사례" 에 대해 다뤄보겠습니다.
'개발자 면접 질문' 카테고리의 다른 글
| 개발자 면접 질문 – gRPC와 REST API의 차이점 (0) | 2025.02.17 |
|---|---|
| 개발자 면접 질문 – 웹 소켓(WebSocket)과 실시간 통신 (0) | 2025.02.16 |
| 개발자 면접 질문 – CDN(Content Delivery Network)과 성능 최적화 (0) | 2025.02.15 |
| 개발자 면접 질문 – 로드 밸런서(Load Balancer)와 트래픽 분산 완벽 가이드 (0) | 2025.02.14 |
| IT 면접 질문 – DNS의 동작 원리 완벽 정리! (0) | 2025.02.13 |




댓글